
Я не буду убеждать вас в том, что в России с региональными измерениями телевизионной аудитории сегодня все в порядке, в том, что ближайшее будущее региональных измерений я вижу в розовом свете, и что проблем не существует. Проблемы, конечно, есть, но они не уникальны для России. Есть общая проблема надежности измерений малых аудиторий, она существует во всем мире, в любых панелях.
Понятию «малая аудитория» соответствуют:
- локальная аудитория отдельного города;
- аудитория и национального и регионального телеканала с малым охватом;
- аудитория телеканала с ограниченной зоной вещания;
- узкая целевая группа на любом телеканале;
- аудитория низкорейтингового временного интервала для любого телеканала (например, утренние передачи).
Итак, проблема «малых аудиторий» - общая для ВСЕХ панелей во ВСЕХ странах мира.
Надежность измерения малых аудиторий
Самый очевидный способ решения проблемы малых аудиторий - это увеличение всей выборки исследования. Возможно также целенаправленное увеличение выборки для измерения конкретной малой аудитории - так называемые «флюсы». Третьим способом повышения надежности измерений является агрегирование результатов измерения. Эти три способа не взаимоисключающие, они могут друг друга дополнять. Например, в национальном исследовании TV-Index компании TNS Gallup Media в ряде городов флюсы уже имеются, но сегодня уже очевидно, что дальнейшее увеличение флюсов неэффективно (чуть позже мы вернемся к этому вопросу).
Что в этом случае нам рекомендует международный опыт? Международный опыт говорит, что если объект измерения мал для представления результатов по отдельным спотам или программам, то для повышения надежности результатов данные нужно агрегировать.
Что же стоит за этим понятием - «агрегирование»?
Агрегирование данных есть повышение надежности главной информации за счет отказа от второстепенной.
То есть здесь действует принцип «Лучше меньше - да лучше». Какая информация будет являться главной, а какая второстепенной, зависит от целей использования той или иной «измерительной» информации. Например, информация о рейтинге отдельного спота в принципе может представлять интерес, но является явно второстепенной по сравнению с главной информацией - о рекламной кампании в целом, ее GRP, Reach, Frequency, определяющих как затраты на рекламу (исходя из цены за пункт GRP), так и эффективность ее размещения.
Надежность агрегированных оценок аудиторных показателей
Какие же данные можно агрегировать с целью увеличения надежности оценок аудиторных показателей?
- Если речь идет о рейтингах рекламной кампании, то от оценки рейтингов спотов и блоков следует перейти к оценке GRP и среднего рейтинга по флайтам и кампаниям, забыв о рейтинге отдельно взятого спота. И дальше оперировать GRP и средним рейтингом по кампании.
- Если мы говорим о регулярных программах на малом канале или в утренние часы, где трудно получить надежную оценку рейтинга каждого выпуска, - то для увеличения надежности данных от оценки рейтингов отдельных выпусков следует перейти к оценке среднего рейтинга программы за определенный период времени (неделя, месяц).
- Если рассматривается отдельно взятое эфирное событие (программа, спот, минута) или утренний эфир, то здесь проблема остается, но и она не является нерешаемой. Здесь агрегирование может производиться по временным интервалам. Оптимальный временной интервал, по которому имеет смысл агрегировать данные, - 15 минут. При увеличении этого интервала эффект агрегирования уменьшается, сглаживается (в принципе агрегирование данных применимо для любой телевизионной панели, национальной или локальной, но размер выборки национальной панели вполне достаточен для решения практически всех задач без дополнительного агрегирования по 15-минутным интервалам).
Погрешности оценок рекламной кампании из 150 спотов с объемом GRP=400 за 4 недели на городской панельной выборке размером 200 респондентов с применением агрегирования
| Tolerance Intervals for 95% Confidence Level : | |||
| ± absolute | ± relative (%) | ||
| Sample | 200 | ||
| Quantity | 150 | ||
| GRP | 400 | 60 | 15 |
| Reach % | 75 | 6 | 8 |
| Average Spot TVR (%) | 2,7 | 0,4 | 15 |
Погрешность оценки рейтинга отдельного спота на той же выборке
| Spot TVR (%) | 2,7 | 2,2 | 84 |
15-минутное агрегирование при оценке отдельного эфирного события
Агрегирование до 15 минут по пиплметрам
Правило 15-минутного агрегирования пиплметрических данных:
Каждому i-му респонденту в каждом j-м 15-минутном интервале присваивается вероятность смотрения k-го канала - pijk, равная 1/15 длительности смотрения этого канала в этой 15-минутке.
Итак, Pijk - вероятность того, что i-й респондент видел произвольную минуту k-го канала в j-ой 15-минутке.
Особенности агрегирования по пиплметрам:
1. Информация о смотрении канала не теряется, даже если респондент смотрел его только 1 минуту.
2. Совместимость результатов измерения с результатами национального пиплметрового измерения.
3. Агрегирование повышает надежность данных, так как усредняет оценки рейтингов по нескольким событиям (минутам).
4. Агрегирование до 15 минут по пиплметрам осуществляется программно, одинаково для всех, при этом не происходит потери информации - учитываются все минуты смотрения.
Надежность данных локальных телевизионных измерений с выборкой в 200 респондентов увеличивается в 1.2-3.7 раза.
Агрегирование до 15 минут в дневниках
В исследованиях с использованием дневников работает иное агрегирование, хотя тоже 15-минутное. Здесь каждый респондент субъективно, в меру индивидуальных особенностей его дисциплины, памяти и ощущения времени отображает реальный процесс смотрения в 15-минутные записи в дневнике.
Правило агрегирования до 15 минут в дневниках:
Всей 15-минутке респондент должен приписать смотрение того канала, который он смотрел, по его мнению, не менее 8 минут в этой 15-минутке.
Особенности агрегирования в дневниках:
1. Агрегирование осуществляется субъективно респондентом, различно для разных каналов и передач.
2. Происходит потеря информации о коротких (<15 мин) смотрениях.
3. Результаты измерения несовместимы с результатами национального пиплметрового измерения.
4. Агрегирование не повышает надежность данных, так как отсутствует усреднение по нескольким событиям.
5. Программная поддержка осуществляется новой версией Palomars.
Локальные рынки - расчетный эффект агрегирования по временным интервалам
| число событий (минут) | ||||||||||||||
| к о р р е л я ц и я | 0,00 0,10 0,20 0,30 0,40 0,50 0,60 0,70 0,80 0,90 1,00 | 1 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 1,0 | 5 2,2 1,9 1,7 1,5 1,4 1,3 1,2 1,1 1,1 1,0 1,0 | 10 3,2 2,3 1,9 1,6 1,5 1,3 1,3 1,2 1,1 1,0 1,0 | 15 3,9 2,5 2,0 1,7 1,5 1,4 1,3 1,2 1,1 1,1 1,0 | 20 4,5 2,6 2,0 1,7 1,5 1,4 1,3 1,2 1,1 1,1 1,0 | 25 5,0 2,7 2,1 1,7 1,5 1,4 1,3 1,2 1,1 1,1 1,0 | 30 5,5 2,8 2,1 1,8 1,5 1,4 1,3 1,2 1,1 1,1 1,0 | 35 5,9 2,8 2,1 1,8 1,5 1,4 1,3 1,2 1,1 1,1 1,0 | 40 6,3 2,9 2,1 1,8 1,6 1,4 1,3 1,2 1,1 1,1 1,0 | 45 6,7 2,9 2,1 1,8 1,6 1,4 1,3 1,2 1,1 1,1 1,0 | 50 7,1 2,9 2,2 1,8 1,6 1,4 1,3 1,2 1,1 1,1 1,0 | 55 7,4 2,9 2,2 1,8 1,6 1,4 1,3 1,2 1,1 1,1 1,0 | 60 7,7 2,9 2,2 1,8 1,6 1,4 1,3 1,2 1,1 1,1 1,0 |
Локальные рынки - эффект агрегирования по временным интервалам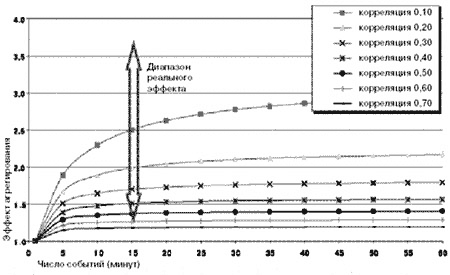
Применение 15-минутного агрегирования к реальным данным городской панели с 200 респондентами
Проверка на реальных панельных данных по Нижнему Новгороду в феврале 2003 г. дала такие результаты.
Фактический эффект уменьшения погрешности при агрегировании до 15 минут составил:
- минимум - 1.2
- максимум - 3.7
- средний - 1.9
То есть, благодаря агрегированию, доверительный интервал оценки рейтинга сократился от 1,2 раз (минимум) до 3,7 раз (максимум), в зависимости от канала и времени суток.
При этом на низкорейтинговых временных интервалах и/или каналах эффект усиливается, так как корреляция смотрения разных минут в низкорейтинговой 15-минутке, как правило, ниже, чем в высокорейтинговой. Например, сокращение погрешности для рейтингов Первого канала с применением агрегирования равно 1,7, а сокращение погрешности для рейтингов канала СТС равно 2,1, то есть работает эффект «усиления там, где нужнее».
Агрегирование - эквивалент увеличения выборки
Эффект 15-минутного агрегирования, с точки зрения надежности данных, становится эквивалентен увеличению выборки. Так, допустим, агрегирование до 15 минут на локальных панелях для 5% рейтинга соответствует увеличению выборки от реальных 200 респондентов до 300, или даже 700 «виртуальных» респондентов в зависимости от канала и времени суток.
Эквивалентное увеличение существующей фактической выборки в 200 респондентов на локальных рынках
| Эффект агрегирования при TVR=5% | ||||
| нет | мин. | средн. | макс. | |
| Эффект | 1 | 1,2 | 1,9 | 3,7 |
| 95% доверительный полуинтервал | 3,0 | 2,5 | 1,6 | 0,8 |
| Эквивалентная выборка | 200 | 288 | 722 | 2738 |
Доверительный интервал оценки рейтинга одной минуты
Эта формула хорошо известна тем, кто работает с рейтинговыми данными. Она позволяет определить оценку доверительного интервала рейтинга одной минуты или одного спота.
Можно быть уверенным на L% (уровень доверия), что действительная величина рейтинга минуты лежит в интервале с центром, равным оценке p, полученной по панельной выборке, и границами, отстоящими от нее на:
![]()
| L(%) | K |
| 70 80 90 95 99 | 1,04 1,28 1,64 1,96 2,58 |
где K - коэффициент, зависящий от требуемого уровня доверия (K=1.96 при L=95%),
p - выборочная оценка рейтинга (TVR),
N - эффективный размер выборки
Но следует помнить о том, что совершенно не корректно применять эту формулу к средним оценкам, к оценкам агрегирования. В этом случае формула для доверительного интервала оценки рейтинга t минут или t спотов с учетом агрегирования будет иметь иной вид:
![]()
где K - коэффициент, зависящий от требуемого уровня доверия (K=1.96 при L=95%),
p - оценка рейтинга на выборке (TVR),
N - эффективный размер выборки,
t - число агрегируемых минут или спотов,
r - корреляция между смотрением агрегируемых событий.
В формулу добавлен коэффициент агрегирования, снижающий погрешность оценки рейтинга. Он зависит от числа агрегируемых минут или спотов и корреляции между смотрением агрегируемых событий, оценку которой можно получить по фактическим результатам и по анализу большого количества предварительных данных.
Известен зарубежный опыт рекомендаций по использованию этой формулы для оценки точности агрегированных данных. В частности, компания Nielsen Media (США) рекомендует для американских локальных измерений при расчете доверительного интервала ежедневной передачи с учетом агрегирования по 5 последовательным дням использовать, в зависимости от среднего рейтинга передачи TVR, следующие коэффициенты корреляции:
| TVR | 1 | 2 | 5 | 7 | 10 | 15 | 20 | 25 |
| r | 0.25 | 0.27 | 0.30 | 0.32 | 0.35 | 0.40 | 0.45 | 0.50 |
Из таблицы мы видим, что чем больше оценка рейтинга, тем больше коэффициент корреляции. Это обеспечивает приятную «избирательность» эффекта агрегирования - «тем сильнее, чем нужнее». Однако рекомендации Nielsen Media не являются рецептом для наших измерений - здесь корреляции могут быть другими. Тем более эти рекомендации не применимы для расчета доверительного интервала оценки GRP рекламной кампании, состоящей не из 1-25 выходов программы на одном канале, а из сотен выходов ролика на разных каналах.
С целью выработки практических рекомендаций нами был проведен анализ данных измерения телеаудитории на региональных рынках.
Результаты анализа показывают, что в широком диапазоне разных рекламных кампаний объемом от 200 GRP для расчета доверительного интервала оценки GRP (и/или среднего рейтинга по кампании) с высокой степенью достоверности можно пользоваться приведенной выше формулой, приняв коэффициент корреляции равным 0,02.
Применимость расчета погрешности оценки GRP локальной кампании по формуле с фиксированной корреляцией r = 0.02 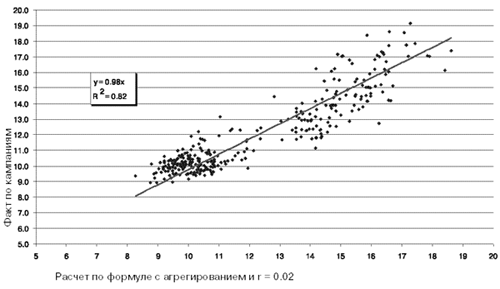
Эффект агрегирования при оценке GRP и среднего рейтинга локальной кампании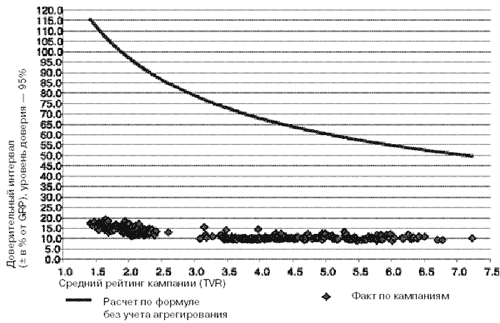
На графике линией показана оценка погрешности измерения GRP (и среднего рейтинга) рекламной кампании на локальном рынке с 200 респондентами в панели, рассчитанная по формуле без учета эффекта агрегирования. Видно, что для кампании со средним рейтингом 2% погрешность оказывается 100 процентной, то есть средний рейтинг может колебаться в пределах его оценки. Точки - результат оценок, полученных на реальных данных, по реальным кампаниям (здесь приведены данные по разным рекламным кампаниям как на местных, так и на федеральных каналах) со средним GRP от 200 до 1,5 тыс. за 4 недели). Мы видим, что чем меньше средний рейтинг кампании, тем больше эффект агрегирования.
На основании проведенного анализа можно дать практический рецепт по работе с агрегированными данными на существующих локальных панелях. Мы видим, что практически все рекламные кампании с GRP больше 200 за 4 недели и со средним рейтингом больше 2,5 удовлетворяют принятым на рынке условиям, то есть погрешность GRP при расчете стоимости рекламной кампании по GRP составит не более 15%.
Доверительный интервал оценки GRP кампании (± в % от GRP) в зависимости от GRP и уровня среднего рейтинга кампании (TVR<2.5 или TVR>2.5)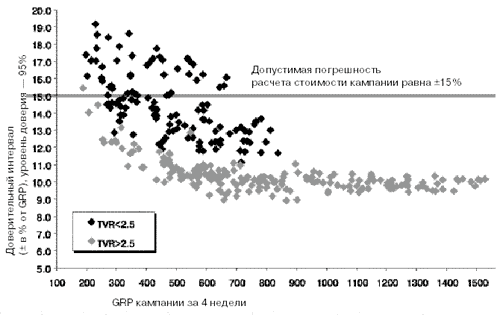
На графике (рис. 7) серым цветом показаны оценки для кампаний со средним уровнем рейтинга больше 2,5 (TVR>2,5). Черным - те кампании, которые имели рейтинг меньше 2,5. Видно, что все локальные кампании с GRP>200 и средним TVR>2.5 удовлетворяют требованию оценки GRP с погрешностью не более 15%, принятой на нашем рынке. Значительная часть кампаний со средним рейтингом ниже 2,5 (черный цвет) имеют погрешность выше 15%, но это лишь означает, что с кампаниями такого уровня следует быть более аккуратными и воспользоваться в каждом конкретном случае приведенной выше формулой оценки погрешности с учетом агрегирования.
Современные условия развития региональных измерений телеаудитории
Современные условия измерения телеаудитории в России (опережающий рост региональных рынков телерекламы - доля бюджета региональной ТВ-рекламы на российском телевидении, по данным РАРА, в 2002 г. составляла 21% против 14% в 2001 г. и, соответственно, рост спроса на региональные телеизмерения) таковы, что региональные измерения в 15 из 40 городов национальной панели компании TNS Gallup Media уже не соответствуют структуре рынка.
Существующая и планируемая на 2005-2010 годы национальная панель не обеспечивает роста региональных измерений, соответствующего темпам роста региональных рынков телерекламы. Сегодня достигнуты пределы роста региональных измерений в составе национальной панели TV-Index: локальные флюсы до 200 респондентов, делая выборку непропорциональной, увеличивают ошибку выборки национального измерения. То есть увеличение выборки, которое сегодня производится в некоторых городах, ложится грузом на национальные измерения, из-за таких флюсов эффективная выборка национального измерения уменьшается в 1,2 раза. Говоря другими словами, 1650 домохозяйств панели TV-Index на 84% используется для общероссийского измерения по городам 100+ и на 16% - для региональных измерений в 15 городах.
Международный опыт региональных измерений, в частности США и Китая, подсказывает целесообразность развития самостоятельных локальных панелей, не входящих в национальную панель, а также параллельное развитие пиплметровых и дневниковых панелей в зависимости от уровня развития локального рынка.
К такому же пути развития измерений телеаудитории, на наш взгляд, ведут и темпы роста локальных телерынков в России. Понимание этих тенденций и стремление максимально им соответствовать привело компанию TNS Gallup Media к решению о кардинальном изменении своей стратегии в развитии региональных измерений телеаудитории, начиная с 2004 года.
Читайте также
А видел ли слона? Измерения эффективности медиа
Рынок масс медиа в России: реалии и тенденции 1
Комментарий
Новое сообщение